DeepSeek 本地部署配置
DeepSeek 与 Ollama 的本地部署记录
DeepSeek
蒸馏模型
如果你电脑运行内存为8G那可以下载1.5b,7b,8b的蒸馏后的模型
如果你电脑运行内存为16G那可以下载14b的蒸馏后的模型
我这里选择7b的模型,参数越大,使用DeepSeek的效果越好
搜索出来有很多个版本,区别就是参数不一样。
1.5b,7b,8b,14b,32b,70b,671b
硬件建议
- 7B 模型:至少 8GB 内存
- 14B 模型:推荐 16GB 内存+GPU 加速
- 量化模型(如 Q4):可降低 50% 显存占用
Ollama
Ollama 是一个轻量级的本地 AI 模型运行框架:https://ollama.com/
Ollama 是一个”后台引擎”。
Ollama 支持 Windows、Linux、macOS 平台。
使用方式分为两种
- 终端命令行(
curl)、或者自己写 Python、C++ 代码去直接向它的 API 发送请求。这种方式适合把 AI 接入到你自己的代码项目中。 - 下载一个第三方的图形化界面软件(比如最著名的 Open WebUI,或者 Chatbox)。这些软件连接到 Ollama 的 11434 端口后,你就可以像使用网页版 ChatGPT 一样,有漂亮的聊天对话框、历史记录保存,甚至可以上传文件。
部署
安装 Ollama
将 Ollama 解压到根目录下:
1sudo tar -xvf ollama-linux-amd64.tgz -C /
验证是否安装成功:
1# 验证安装
2ollama --version
3ollama help
开启 Ollama 服务:
1ollama serve
模型下载
DeepSeek 模型
下载 DeepSeek 模型,在 Ollama 服务已经打开的情况下(开两个终端),也可以下载其他版本:
1ollama pull deepseek-r1:1.5b
2ollama pull deepseek-r1:7b
其他版本:切换尾缀即可
1版本:1.5b,适用于一般文字编辑使用(需要 1.1GB 空余空间)
2ollama run deepseek-r1:1.5b
3
4版本:7b,DeepSeek 的第一代推理模型,性能与 OpenAI-o1 相当,包括从基于 Llama 和 Qwen 的 DeepSeek R1 中提取的六个密集模型(需要 4.7GB 空余空间)
5ollama run deepseek-r1:7b
6
7版本:8b(需要 4.9GB 空余空间)
8ollama run deepseek-r1:8b
9
10版本:14b(需要 9GB 空余空间)
11ollama run deepseek-r1:14b
12
13版本:32b(需要 20GB 空余空间)
14ollama run deepseek-r1:32b
15
16版本:70b(需要 43GB 空余空间)
17ollama run deepseek-r1:70b
18
19版本:671b(需要 404GB 空余空间)
20ollama run deepseek-r1:671b
千问模型
下载 qwen3:14b 模型:
1ollama pull qwen3:14b
可以直接输入 ollama run qwen3:14b,Ollama 发现本地没有该模型,会自动进行下载:
1ollama run qwen3:14b
监听与环境变量
在使用 DeepSeek 的时候需要在前台使用:
1ollama serve
2# 开启服务才能使用
配置系统环境变量:
1# 监听所有的网络端口
2echo 'export OLLAMA_HOST="0.0.0.0"' >> ~/.bashrc
3echo 'export OLLAMA_ORIGINS="*"' >> ~/.bashrc
4# 写入后重启服务
5source ~/.bashrc
6# 重新开启服务
7ollama serve
对话
1ollama serve # 启动基础推理服务
确认 Ollama 的后台程序到底有没有在正常工作:
1curl http://localhost:11434/
相当于喊了一声”喂,在吗?”,正在监听的 Ollama 听到了,赶紧通过网络回复了一句 ”Ollama is running”。

命令行交互
终端会变成一个类似微信的对话框(前面带个 >>> 提示符),它会自动记住你之前说过的话(也就是有上下文记忆)。
连续对话的聊天室模式:
1ollama serve # 启动基础推理服务
2ollama run deepseek-r1:7b # 另开终端运行模型
3/bye # 结束对话
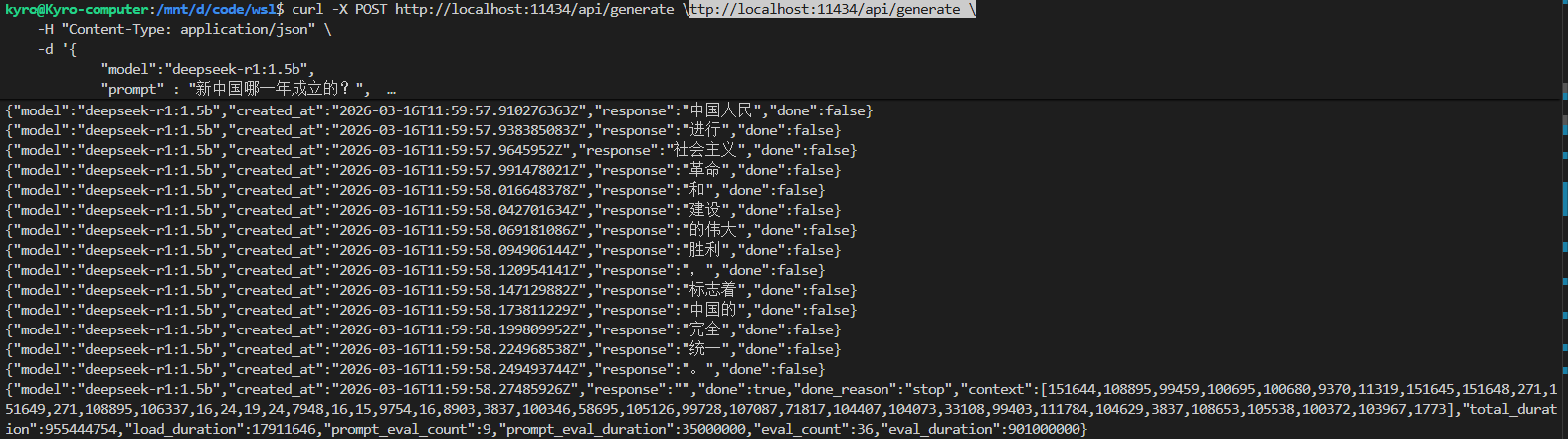
curl 方式
底层通信通道,最原始、最直接的 API 接口调用。一次性的代码请求/响应,包含各种标记的 JSON 机器代码。
流式输出:一边思考,一边把字打出来(打字机效果)。AI 只要生成了哪怕半个词,就会立刻通过网络把这个词发给你。
1curl -X POST http://localhost:11434/api/generate \
2 -H “Content-Type: application/json” \
3 -d '{
4 “model”:”deepseek-r1:1.5b”,
5 “prompt” : “新中国哪一年成立的?”,
6 “stream” : true
7 }'
"model": "deepseek-r1:1.5b" 告诉 Ollama 后台,你要唤醒并使用哪一个具体的 AI 模型(指定大脑)。
"prompt": "hello" 提示词/输入内容
"stream": true 流式传输开关,当为 false(关闭)时:它会在后台把整篇长篇大论全部写完,然后一次性打包发给你。
Python 方式
创建 chat.py 文件:
1nano chat.py
复制粘贴代码:
1import urllib.request
2import json
3import sys
4
5def chat_with_ollama(prompt):
6 url = "http://localhost:11434/api/generate"
7 # 构建发给大模型的数据包
8 data = {
9 "model": "deepseek-r1:1.5b",
10 "prompt": prompt,
11 "stream": False
12 }
13
14 # 将数据打包为 JSON 格式并设置请求头
15 req = urllib.request.Request(
16 url,
17 json.dumps(data).encode('utf-8'),
18 {'Content-Type': 'application/json'}
19 )
20
21 try:
22 # 发送请求并接收回复
23 with urllib.request.urlopen(req) as response:
24 result = json.loads(response.read().decode('utf-8'))
25 print("\n🤖 DeepSeek 回复:\n")
26 print(result.get("response", "没有获取到回复。"))
27 except Exception as e:
28 print(f"\n❌ 请求失败,请检查 Ollama 是否在运行。错误信息: {e}")
29
30if __name__ == "__main__":
31 # 检查是否在命令行里输入了问题
32 if len(sys.argv) > 1:
33 user_input = sys.argv[1]
34 print(f"正在思考: {user_input} ... (请稍等)")
35 chat_with_ollama(user_input)
36 else:
37 print("请提供一个问题!例如: python3 chat.py \"你好\"")
保存并退出。
在 nano 编辑器中,按照以下键盘顺序操作来保存:
- 按
Ctrl + O(字母 O,代表保存,会提示你文件名,直接按回车确认) - 按
Enter(回车) - 按
Ctrl + X(代表退出编辑器)
1python3 chat.py "新中国哪一年成立的?"

其它
其它指令
1# ========== 基础命令 ==========
2ollama --version # 查看版本
3
4# ========== 服务管理 ==========
5ollama serve # 开启服务(必须先启动才能使用)
6
7# ========== 模型管理 ==========
8ollama list # 查看已下载的所有模型
9ollama pull <model-name> # 下载模型
10ollama rm <model-name> # 删除模型
11ollama show <model-name> # 查看模型信息
12
13# ========== 运行管理 ==========
14ollama ps # 查看运行中的模型
15ollama run <model-name> # 启动模型(进入交互模式)
16ollama stop <model-name> # 关闭模型
17
18# ========== 交互模式内 ==========
19Ctrl + D # 退出交互模式
20/bye # 退出交互模式(同上)
示例:
1ollama pull deepseek-r1:1.5b
2ollama rm deepseek-r1:1.5b
3ollama rm qwen:0.5b
4ollama show qwen3:14b
5ollama stop qwen3:14b
IP 端口
http://localhost:11434/
IP 地址 = 大楼的街道地址(决定了数据要送到哪台电脑)。
端口 (Port) = 大楼里的房间号(决定了数据由电脑里的哪个软件来接收)。因为你的电脑同时运行着很多程序(微信、浏览器、Ollama),必须用端口号把它们区分开。11434 就是 Ollama 专属的房间号。
内向封闭
http://localhost:11434/
本机浏览器显示 Ollama is running。
用来自己跟自己通信,同一局域网下的其他设备(比如你的手机、其他电脑)是绝对无法通过 localhost 访问你这台电脑上的 Ollama 的。
外向开放型
http://192.168.1.100:11434/
用来跨设备通信的!只要在同一个 Wi-Fi 或局域网下,任何设备都可以通过这个地址找到你的电脑。
Ollama 只监听 localhost(只听自己人的)。配置了 0.0.0.0 之后,Ollama 不仅监听 localhost,同时也监听 192.168.1.100 这个网卡接口,允许局域网里的手机、开发板来向它请教问题。
1OLLAMA_HOST="0.0.0.0"
参考资料
- Ollama 中文镜像 - Ollama 官方中国镜像加速站
- Ollama 菜鸟教程 - 从零开始的 Ollama 入门指南
- Ollama 实战指南 - 知乎 - 详细的 Ollama 使用案例与技巧
GitHub Discussions
评论区
使用 GitHub 登录,欢迎友好交流。