信息量与熵(第二章)
自信息量、熵、联合熵、条件熵与互信息
第二章 信息量与熵
本章主要讨论以下几个核心概念:
- 自信息量
- 总自信息量
- 信息熵
- 联合熵
- 条件熵
- 互信息量
- 连续型随机变量的熵
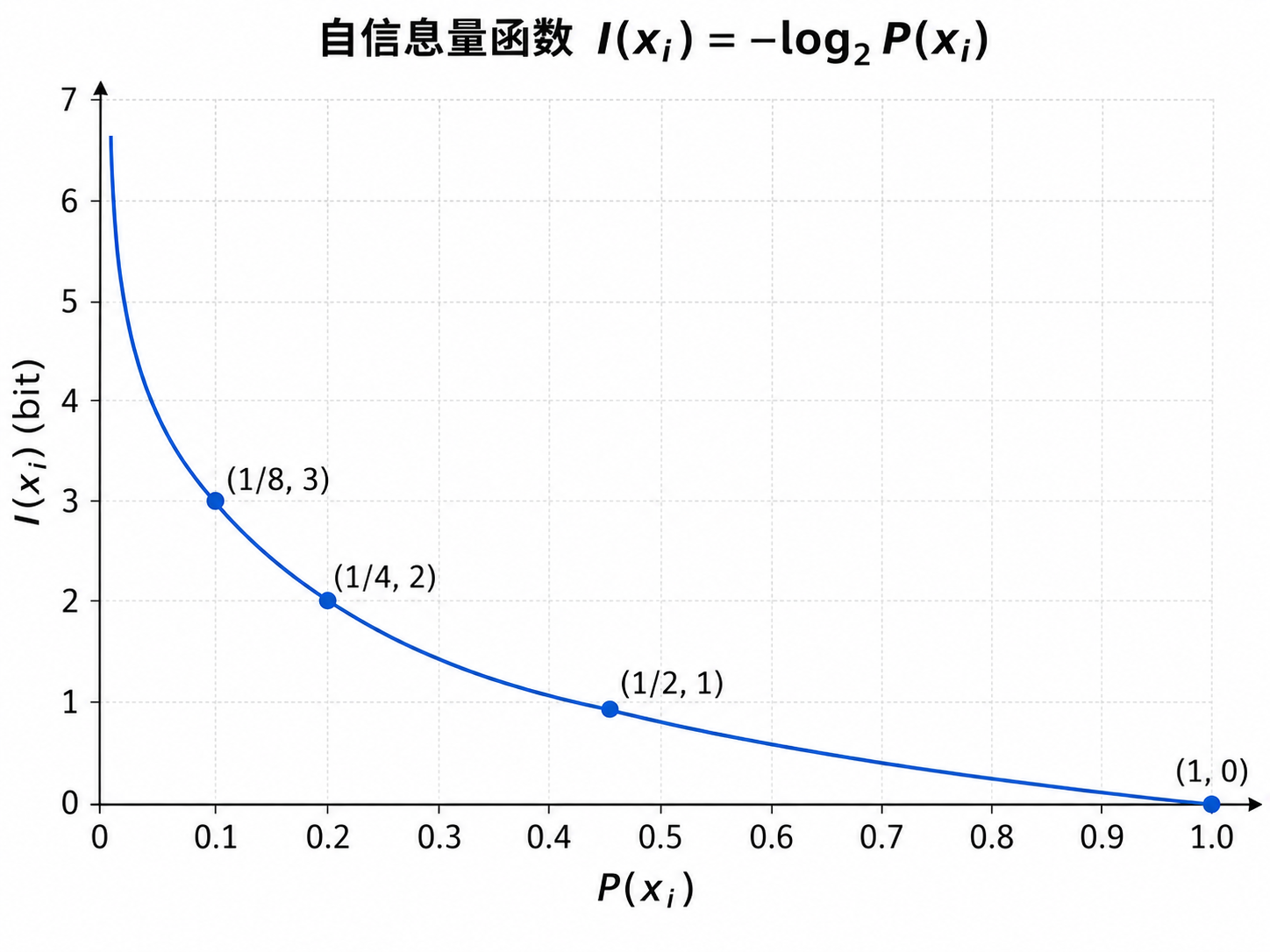
1. 自信息量
单个事件或符号 \(x_i\) 的自信息量定义为:
其中, \(P(x_i)\) 表示事件 \(x_i\) 发生的概率。
单位
当对数底为 \(2\) 时,单位为 \(\text{bit}\) 。
直观理解
- 事件越罕见,发生时带来的信息量越大,当 \(p(x_i)=0\) 时, \(I(x_i)=\infty\)
- 事件越常见,发生时带来的信息量越小,当 \(p(x_i)=1\) 时, \(I(x_i)=0\)
- 若 \(P(x_i) = 1\) ,则 \(I(x_i) = 0\) ,说明确定发生的事件不提供新信息
2. 总自信息量
若一个符号序列中,不同符号 \(x_i\) 分别出现 \(n_i\) 次,则总自信息量为:
其中:
- \(m\) :符号种类数
- \(i\) :符号索引, \(i = 1,2,\dots,m\)
- \(n_i\) :符号 \(x_i\) 在序列中出现的次数
- \(I(x_i)\) :符号 \(x_i\) 的自信息量
这个公式表示:一个序列的总信息量,等于各类符号信息量按出现次数累加。
3. 信息熵
信息熵是随机变量平均不确定性的度量,也可以理解为“平均每次观测所获得的信息量”。
设离散随机变量 \(X\) 的可能取值为 \(x_1, x_2, \dots, x_n\) ,其概率分布为 \(p(x_i)\) ,则熵定义为:
直观理解
- 熵越大,说明结果越难预测,系统越不确定
- 熵越小,说明结果越容易预测,系统越确定
- 当某个结果必然发生时,熵最小,为 \(0\)
单位
熵的单位通常为 \(\text{bit}\) 。
特殊情况
- 若 \(X\) 只有一个确定结果,则
- 若 \(X\) 在 \(n\) 个结果上等概率分布,即
则熵最大,且
4. 联合熵
联合熵用于描述两个随机变量 \(X\) 和 \(Y\) 作为整体时的不确定性。
定义为:
其中, \(p(x,y)\) 表示事件 \(X=x\) 与 \(Y=y\) 同时发生的联合概率。
理解
- \(H(X)\) 描述 \(X\) 单独的不确定性
- \(H(Y)\) 描述 \(Y\) 单独的不确定性
- \(H(X,Y)\) 描述二者合在一起后的总不确定性
5. 条件熵
条件熵表示:在已知一个随机变量之后,另一个随机变量还剩下多少不确定性。
定义 1
在已知 \(X\) 的情况下, \(Y\) 的条件熵为:
定义 2
也可以写成加权平均形式:
同理,在已知 \(Y\) 的情况下, \(X\) 的条件熵为:
直观理解
- 已知的信息越多,剩余不确定性通常越小
- 若知道 \(X\) 后就能完全确定 \(Y\) ,则 \(H(Y|X)=0\)
- 若 \(X\) 和 \(Y\) 相互独立,则知道 \(X\) 不会减少 \(Y\) 的不确定性,此时 \(H(Y|X)=H(Y)\)
6. 联合熵与条件熵的关系
联合熵可以分解为:
同样也有:
这说明:整体不确定性 = 先知道一个变量所需的信息量 + 在此基础上确定另一个变量还需的信息量。
7. 互信息量
互信息量用于衡量:知道一个随机变量后,能使另一个随机变量的不确定性减少多少。
定义为:
由于互信息是对称的,所以也有:
还可以写成:
直观理解
- \(I(X;Y)\) 越大,说明 \(X\) 和 \(Y\) 相关性越强
- \(I(X;Y)=0\) ,说明 \(X\) 和 \(Y\) 相互独立
- 若知道 \(X\) 后可以完全确定 \(Y\) ,则互信息达到较大值
物理意义
互信息量描述的是两个变量共享的信息量,也就是“重复的不确定性部分”。
8. 几个常用性质
1. 熵非负
2. 条件熵非负
3. 条件熵不大于原熵
意思是:已知额外信息后,不确定性不会增加。
4. 联合熵不大于单独熵之和
当且仅当 \(X\) 与 \(Y\) 相互独立时取等号。
5. 互信息非负
9. 简单例子
设随机变量 \(X\) 表示抛一枚均匀硬币的结果:
- 正面:概率为 \(\frac{1}{2}\)
- 反面:概率为 \(\frac{1}{2}\)
则其熵为:
这说明:一次公平抛硬币平均提供 \(1\,\text{bit}\) 信息。
若硬币极不均匀,例如:
- 正面:概率为 \(0.99\)
- 反面:概率为 \(0.01\)
则熵会远小于 \(1\,\text{bit}\) ,因为结果已经比较容易预测。
10. 连续型随机变量的熵
对于连续型随机变量,若其概率密度函数为 \(f(x)\) ,则定义微分熵为:
注意
- 这里的熵称为微分熵
- 微分熵与离散熵的性质不完全相同
- 微分熵可以为负,因此不能直接照搬离散熵的直觉
11. 本章小结
- 自信息量描述单个事件发生后带来的信息多少
- 熵描述随机变量平均意义下的不确定性
- 联合熵描述多个变量整体的不确定性
- 条件熵描述已知部分信息后剩余的不确定性
- 互信息量描述两个变量之间共享的信息多少
这一章的核心主线可以概括为:
单个事件的信息量 -> 平均信息量 -> 多变量之间的信息关系
GitHub Discussions
评论区
使用 GitHub 登录,欢迎友好交流。