信源编码(第五章)
哈夫曼编码与香农编码
一、基本概念
1.1 信源符号熵
信源符号熵 \(H(X)\) 的计算公式:
\[
H(X) = -\sum_{i=1}^{n} p_i \log_2 p_i
\]
其中 \(p_i\) 为第 \(i\) 个符号出现的概率。
1.2 平均码长
平均码长 \(\bar{K}\) 的计算公式:
\[
\bar{K} = \sum_{i=1}^{n} p_i K_i
\]
其中 \(K_i\) 为第 \(i\) 个符号的码长, \(p_i\) 为对应概率。
说明:平均码长 = 码长 × 概率
1.3 编码效率
编码效率 \(\eta\) 的计算公式:
\[
\eta = \frac{H(X)}{\bar{K}}
\]
其中:
- \(H(X)\) 为信源熵(理论最优平均码长)
- \(\bar{K}\) 为实际平均码长
说明:编码效率越接近 1(或 100%),说明编码方案越优。
二、哈夫曼编码
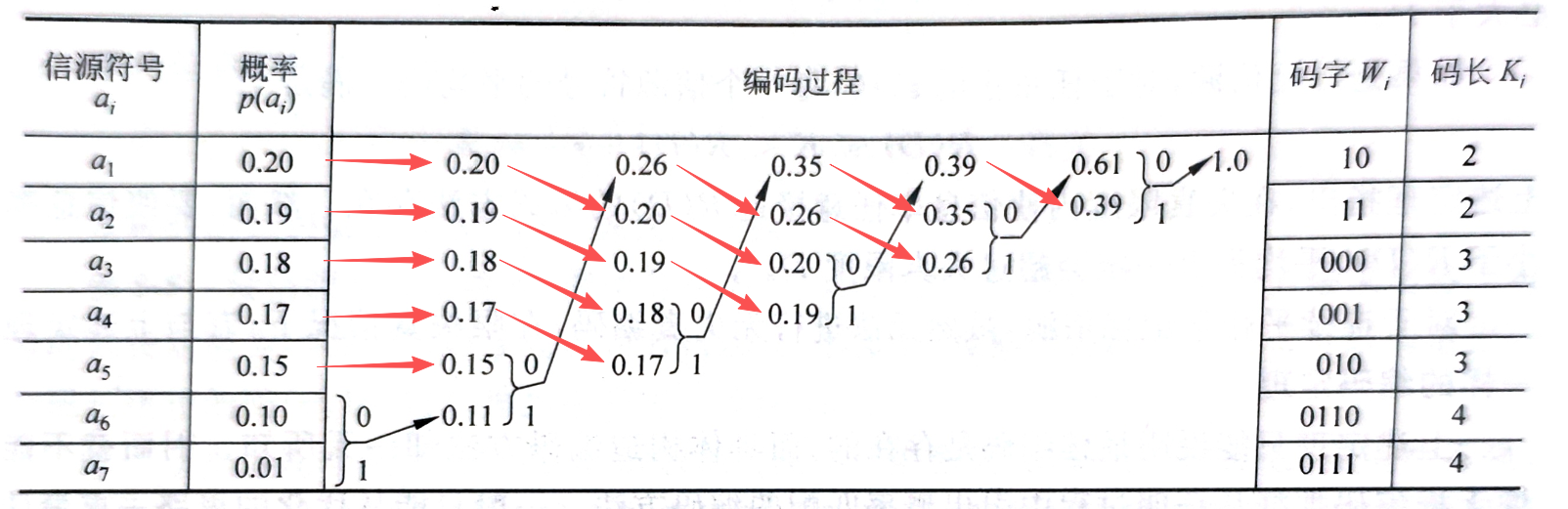
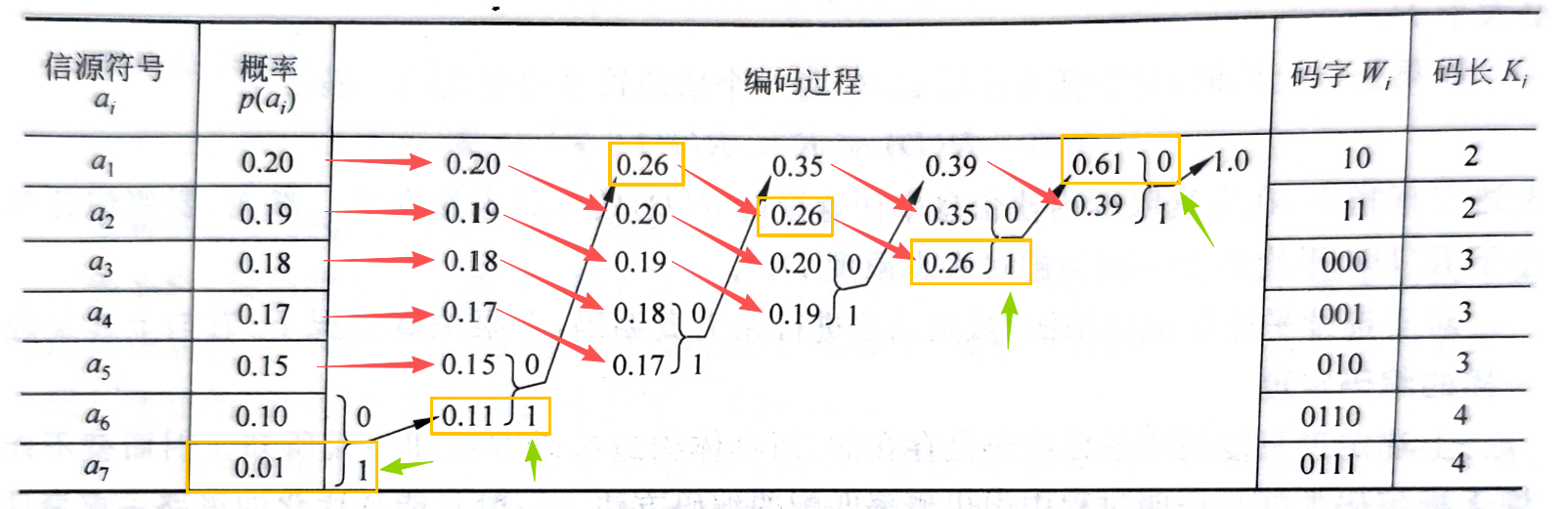
2.1 编码步骤
- 排序:把信源符号按概率从大到小排列(最上面排最大的)
- 合并:从最下面取最小的两个概率合并
- 重排:把新概率放回原来的队列中重新排序
- 重复:重复"取最小两个并合并",直到最后只剩一个总概率为 1 的根节点
- 标注:将合并的分支上标
0,下标1
2.2 读码规则
重要提示:
- 读码字时要从右往左读(逆向读取)
- 只有分支标注的
0和1才编码,最后右侧合成的总概率 1 不作为编码 - 从最后一级(最右侧)寻找回到最左侧对应信源的路径
2.3 编码示例: \(a_7\) 的编码路径
以图片中的 \(a_7\) 为例,演示如何读取编码:
第一步(从 1.0 往左)
- 最右侧的 1.0 由 0.61 和 0.39 合并而成
- \(a_7\) 的概率 0.01 包含在 0.61 这个分支中
- 该分支标注:
0
第二步(从 0.61 往左)
- 0.61 由 0.35 和 0.26 合并而成
- 0.01 包含在下方的 0.26 中
- 该分支标注:
1
第三步(从 0.26 往左)
- 0.26 由 0.15 和 0.11 合并而成
- 0.01 属于下方的 0.11
- 该分支标注:
1
第四步(从 0.11 往左,到达目标)
- 0.11 由 0.10 和 0.01 合并而成
- 找到目标 \(a_7\) (0.01)
- 该分支标注:
1
结果:
\(a_7\)
的哈夫曼编码为 0111(从右往左读得到的顺序)
三、香农编码
3.1 编码原理
码长公式(常见教材版本):
\[
K_i = \lfloor -\log_2 p_i \rfloor + 1
\]
累加概率:
\[
Q_i = \sum_{j=1}^{i-1} p_j
\]
3.2 小数十进制转二进制方法
转换规则:将小数部分不断乘以 2,取整数部分作为二进制位
示例 1:将 0.62 转换为二进制
| 步骤 | 计算 | 整数部分 | 二进制位 |
|---|---|---|---|
| 1 | 0.62 × 2 = 1.24 | 1 | 1 |
| 2 | 0.24 × 2 = 0.48 | 0 | 0 |
| 3 | 0.48 × 2 = 0.96 | 0 | 0 |
| 4 | 0.96 × 2 = 1.92 | 1 | 1 |
| 5 | 0.92 × 2 = 1.84 | 1 | 1 |
结果:0.62 ≈ 0.10011…₂
示例 2:将 0.80 转换为二进制
| 步骤 | 计算 | 整数部分 | 二进制位 |
|---|---|---|---|
| 1 | 0.80 × 2 = 1.60 | 1 | 1 |
| 2 | 0.60 × 2 = 1.20 | 1 | 1 |
| 3 | 0.20 × 2 = 0.40 | 0 | 0 |
| 4 | 0.40 × 2 = 0.80 | 0 | 0 |
| 5 | 0.80 × 2 = 1.60 | 1 | 1 |
结果:0.80 = 0.11001100…₂(循环)
四、综合例题
题目
设有离散无记忆信源 \(P(X) = \{0.37, 0.25, 0.18, 0.10, 0.07, 0.03\}\)
要求:
- 求该信源符号熵 \(H(X)\)
- 用哈夫曼编码编成二元变长码,计算其编码效率
- 用香农编码编成二进制变长码,计算其编码效率
4.1 信源熵 \(H(X)\)
公式:
\[
H(X) = -\sum_{i=1}^{6} p_i \log_2 p_i
\]
代入计算:
\[
H(X) = -(0.37\log_2 0.37 + 0.25\log_2 0.25 + 0.18\log_2 0.18 + 0.10\log_2 0.10 + 0.07\log_2 0.07 + 0.03\log_2 0.03)
\]
结果:
\[
\boxed{H(X) \approx 2.2286 \text{ bit/符号}}
\]
4.2 哈夫曼编码
编码结果
| 符号 | 概率 \(p_i\) | 哈夫曼码 | 码长 \(K_i\) | 推导路径 |
|---|---|---|---|---|
| \(x_1\) | 0.37 | 00 | 2 | 0.37 → 0.62 → 1.0 |
| \(x_2\) | 0.25 | 01 | 2 | 0.25 → 0.62 → 1.0 |
| \(x_3\) | 0.18 | 11 | 2 | 0.18 → 0.38 → 1.0 |
| \(x_4\) | 0.10 | 100 | 3 | 0.10 → 0.20 → 0.38 → 1.0 |
| \(x_5\) | 0.07 | 1010 | 4 | 0.07 → 0.10 → 0.20 → 0.38 → 1.0 |
| \(x_6\) | 0.03 | 1011 | 4 | 0.03 → 0.10 → 0.20 → 0.38 → 1.0 |
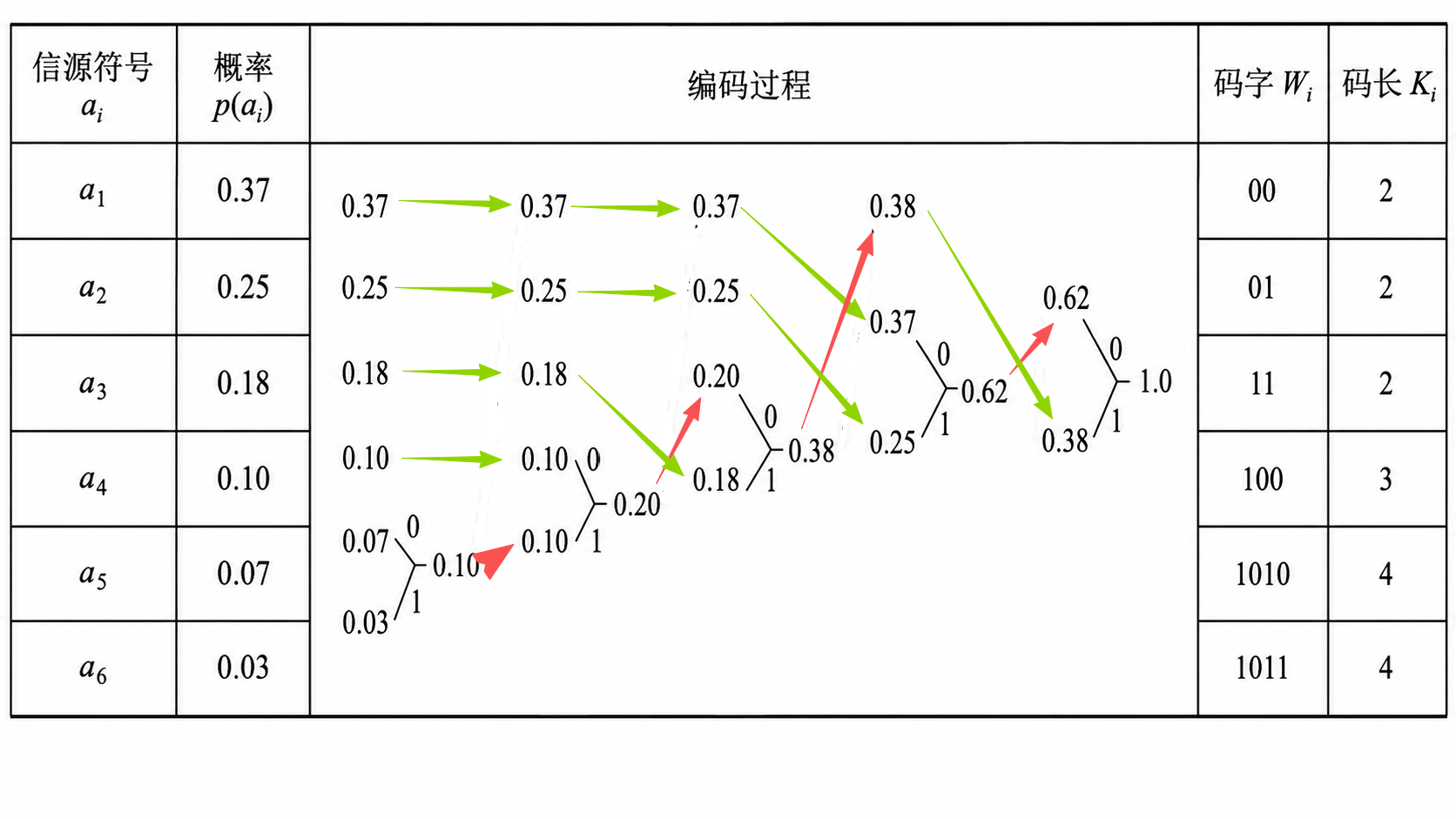
注意:哈夫曼编码不唯一,具体码字取决于合并时的上下分支标注顺序,但平均码长和编码效率相同。
平均码长
\[
\bar{K}_H = \sum p_i K_i
\]
\[
\bar{K}_H = 0.37 \times 2 + 0.25 \times 2 + 0.18 \times 2 + 0.10 \times 3 + 0.07 \times 4 + 0.03 \times 4
\]
\[
\bar{K}_H = 2.30
\]
编码效率
\[
\eta_H = \frac{H(X)}{\bar{K}_H} = \frac{2.2286}{2.30} \approx 0.9689
\]
\[
\boxed{\eta_H \approx 96.89\%}
\]
4.3 香农编码
编码结果
| 符号 | 概率 \(p_i\) | \(-\log_2 p_i\) | 码长 \(K_i\) | 累加概率 \(Q_i\) | \(Q_i\) 的二进制 | 香农码 |
|---|---|---|---|---|---|---|
| \(a_1\) | 0.37 | 1.43 | 2 | 0.00 | 0.0000… | 00 |
| \(a_2\) | 0.25 | 2.00 | 2 | 0.37 | 0.0101… | 01 |
| \(a_3\) | 0.18 | 2.47 | 3 | 0.62 | 0.1001… | 100 |
| \(a_4\) | 0.10 | 3.32 | 4 | 0.80 | 0.1100… | 1100 |
| \(a_5\) | 0.07 | 3.84 | 4 | 0.90 | 0.1110… | 1110 |
| \(a_6\) | 0.03 | 5.06 | 6 | 0.97 | 0.111110… | 111110 |
关键步骤说明:
- 对于
\(a_1\)
:
\(Q_1 = 0\)
,二进制为 0.0000…,截取 2 位得
00 - 对于
\(a_2\)
:
\(Q_2 = 0.37\)
,转二进制为 0.0101…,截取 2 位得
01 - 对于
\(a_3\)
:
\(Q_3 = 0.62\)
,转二进制为 0.1001…(见示例1),截取 3 位得
100 - 对于
\(a_4\)
:
\(Q_4 = 0.80\)
,转二进制为 0.1100…(见示例2),截取 4 位得
1100
平均码长
\[
\bar{K}_S = 0.37 \times 2 + 0.25 \times 2 + 0.18 \times 3 + 0.10 \times 4 + 0.07 \times 4 + 0.03 \times 6
\]
\[
\bar{K}_S = 0.74 + 0.50 + 0.54 + 0.40 + 0.28 + 0.18 = 2.64
\]
编码效率
\[
\eta_S = \frac{H(X)}{\bar{K}_S} = \frac{2.2286}{2.64} \approx 0.8441
\]
\[
\boxed{\eta_S \approx 84.41\%}
\]
GitHub Discussions
评论区
使用 GitHub 登录,欢迎友好交流。